
🧠 What is an Index in SQL?
An index in SQL is like a table of contents in a book. It helps the database engine find rows faster without scanning the whole table.
But not all indexes are created equal! The two most common types are:
-
✅ Clustered Index
-
✅ Non-Clustered Index
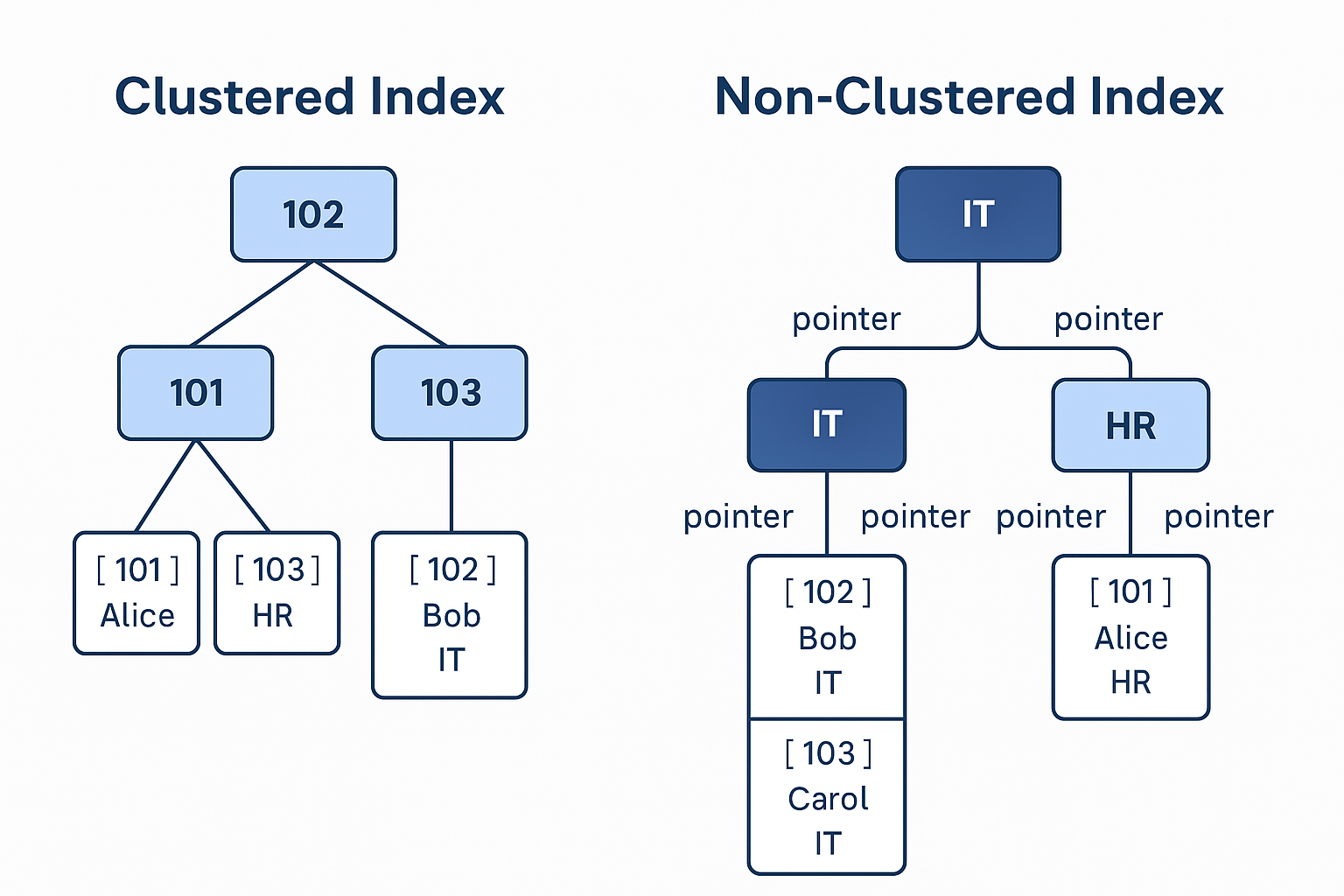
🧩 Difference Between Clustered and Non-Clustered Index
| Feature | Clustered Index | Non-Clustered Index |
|---|---|---|
| Data Storage | Sorts and stores actual data in order | Stores a pointer to the actual data |
| One Per Table? | ✅ Only ONE allowed per table | ❌ Can have multiple |
| Speed (for ranges) | Faster for range queries | Slower for range queries |
| Physical Order | Defines physical order of rows | Does not define physical order |
| Extra Lookup? | ❌ No extra lookup required | ✅ Needs key lookup for actual data |
💡 Real-Life Analogy
📖 Clustered Index:
Imagine a dictionary where words are arranged alphabetically and the actual definition is right there.
📘 Non-Clustered Index:
Now imagine a book index at the back that tells you, “See page 53 for ‘Binary Tree’,” and then you flip to page 53.
-
Clustered Index = content organized and embedded
-
Non-Clustered Index = reference pointing to content elsewhere
🔍 Real-Time SQL Example
Assume you have this Employees table:
✅ Clustered Index (default on primary key):
Behind the scenes, SQL Server sorts the table’s physical storage by EmployeeID.
✅ Non-Clustered Index:
Now, searching WHERE Department = 'IT' uses idx_department to locate rows faster, then jumps to find actual rows using a pointer.
🧬 Why the Names “Clustered” and “Non-Clustered”?
-
Clustered means data is clustered together with the index. Data rows are physically ordered.
-
Non-Clustered means the index is separate from the data, with a pointer (called row locator) to the actual row.
It’s all about how tightly the index and data are stored together!
🔧 What’s Happening Behind the Scene?
Clustered Index:
-
Data is reordered in the background.
-
Think of it like SQL physically organizing pages in a dictionary.
-
Uses a B+ tree structure to navigate sorted data.
Non-Clustered Index:
-
SQL creates a separate structure, like a table of contents.
-
It stores:
-
Indexed column
-
A pointer to the data row (called row ID or RID)
-
🎯 When to Use Clustered vs. Non-Clustered Index?
| Situation | Recommended Index |
|---|---|
| Frequently searched by primary key | ✅ Clustered |
| Range queries (e.g., date ranges) | ✅ Clustered |
| Queries on non-PK columns | ✅ Non-Clustered |
| Want multiple search paths | ✅ Multiple Non-Clustered |
| Tables with lots of inserts/updates | ⚠ Use Clustered wisely (can slow down inserts) |
🎓 Visual Understanding
Imagine this bookshelf:
🟩 Clustered Index
🟦 Non-Clustered Index on Department

🔥 Tricky Interview Questions & Answers
❓ Q1: Can a table have more than one clustered index?
🅰️ ❌ No. Since clustered index reorders the table, only one is allowed.
❓ Q2: Can a table have multiple non-clustered indexes?
🅰️ ✅ Yes! You can create up to 999 non-clustered indexes in SQL Server.
❓ Q3: What is a Covering Index?
🅰️ A non-clustered index that includes all the columns needed by a query. SQL doesn’t need to access the base table.
❓ Q4: What is a Bookmark Lookup (Key Lookup)?
🅰️ It happens when SQL uses a non-clustered index but still needs to lookup the remaining data in the base table.
❓ Q5: Will indexes slow down inserts or updates?
🅰️ Yes. Every time you insert or update data, indexes must also be updated, which can add overhead.
🏁 Conclusion
-
Use a Clustered Index when you want the actual data ordered for fast retrieval.
-
Use Non-Clustered Indexes to create quick lookup paths to non-primary key data.
-
Combine them with understanding of your query patterns and data distribution.